ResNet — 101 with PyTorch

I decided to revisit the concepts of deep learning and chose PyTorch as a framework for this task. I started off with the implementation of a basic neural network in PyTorch using the various tools this framework provides such as Dataloader, the nn module and LR scheduler and more.
I have been mostly using Tensorflow and Keras in my deep learning journey so far. The upgrades that Tensorflow 2 brings with itself are great. But I have to say this, I am just loving PyTorch. Being a python programmer, creating Deep Learning training and inference codes haven’t been so cleaner and detailed for me. The object oriented approach of writing a neural net in PyTorch provides a developer with lot of options. Sequential and the functional modules for creating neural nets can be used in tandem.
As I have been experimenting with the models, I came across the infamous ResNet and thought it would be a good idea to write a small explanation about what ResNets are and how they are differ from ordinary CNNs.
So, How can you make a CNN perform better ? ??
There are more than one way of doing it. One go-to approach is to add more depth to your network.
Now there’s a catch with adding more depth by adding more layers. After one forward pass the optimizer has to update the weights by doing a backprop across the length of the entire neural net. When neural nets are extremely deep, due to repeated multiplication of the gradient (derivative) values in the initial layer with all the values that lie beneath it, the gradient is pushed to a very small and negligible value. The chain rule of derivation which takes place during backpropagation creates this repeated chain of multiplications.

This is often termed as the vanishing gradient problem. Training becomes ineffective after that point.
Kaiming He and CoAuthors from the Microsoft Research team,in December 2015 came up with ResNets (https://arxiv.org/pdf/1512.03385.pdf)
Residual Networks or ResNets is a very clever architecture of adding the input to any CNN block to the output of the same block. Fig 2 shows this trick of adding the input to the output.
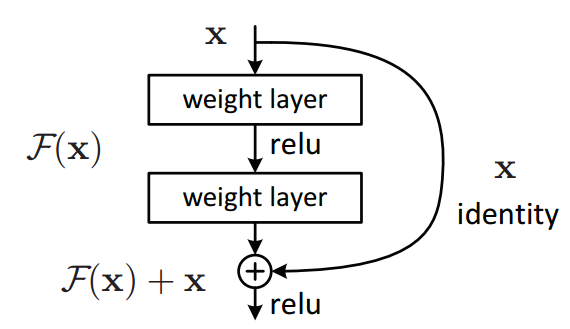
This type of connection is also known as a skip connection. The mapping is called an identity mapping. Adding the input to the output of the CNN block affects the backpropagation step in a good way. Now the larger valued output of the block is not easily zeroed out when repeated derivatives are calculated.
ResNets are widely used in the industry to train super-deep neural networks with very high accuracies.
Let’s go ahead and implement a vanilla ResNet in PyTorch
We will use a class called VanResNet to define our neural net and the forward function. The number of filters in the first layer will be 32 and we are going to increase the number of filters by 2 in the subsequent layers.
As shown in Fig 3, let’s import the necessary modules needed to build our Vanilla ResNet

Now let’s build the conv layers needed for our network. Fig 4 shows the definition of the conv layers along with the fc layers. The first conv layer takes an input channel of 3 and has number of filters as 32. We have used instance and class variables to define the initial filter size and also the number of filters in the first fully connected the layer.

Now let’s see the skip connection being defined in our forward function. In line 4 of Fig 5, we make a copy of the output x as x1. In line 5, right after we run conv3 on the input of the previous layer, we also add the x1 to this, before applying relu and maxpool.

And there you go. That was a small and basic introduction to skip connection and ResNets in PyTorch.
